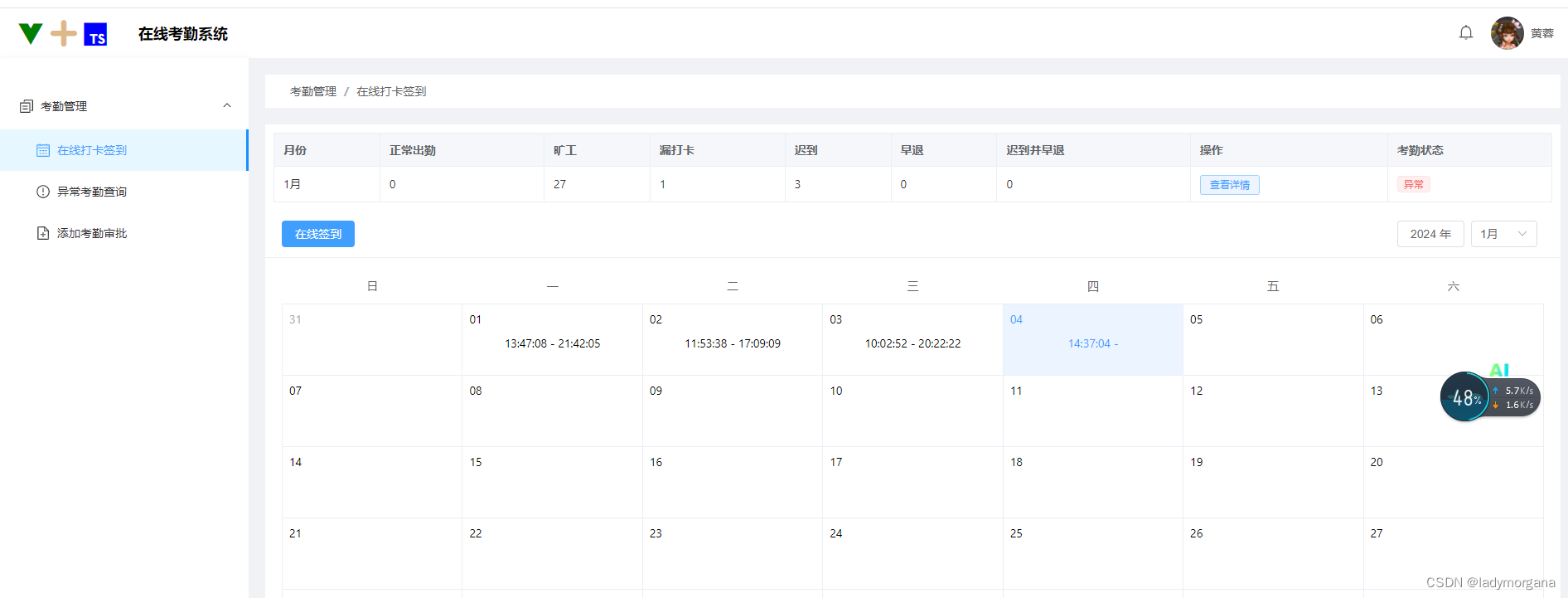
背景
拍摄APP项目上线有一阵了,每天的拍摄数据呈现波动上升状态、业务方需要对数据进行加工,如果能有对未来的数据量的预测就好了 。
目标
在端侧展示拍摄数据可视化趋势图等、并能推断数据(选择预测日期) 简单实现个demo

先写总结
现在来看、出来的东西很简单,但是整个流程时串通起来了。至于什么是tensorflow lite 初识TensorFlow Lite -CSDN博客
总体流程图是这样的 从左侧的数据来源开始、到tensorflow 模型训练 到云上、动态下发、再到预测数据。生产数据的 再次收集数据运行的全流程正循环。 模型训练在本篇下方 其他后续写

一.数据处理
数据来源
目前只有日志数据 以单个数据为维度的: 2023年x月x日 张某 所属部门 拍摄时间 等数据
数据预处理
通过pyhton 统计当日共拍摄多少套、都属于哪个部门
数据清洗
去除前三天刚上线数据(不准)、和当日的数据(未统计完全)等特殊数据
数据分析、抽取
根据数据判断 不光跟当日部门数、时间、还有星期有关 比如 周五周六周天相对较高 将星期也为参数。
输出关系图
sns.pairplot(train_dataset[["拍摄数量","事业部数量","weekday","index"]], diag_kind="kde")
拆分训练数据集和测试数据集
拆除80%的数据进行训练、20%进行测试
train_dataset = dataset.sample(frac=0.8,random_state=0)
test_dataset = dataset.drop(train_dataset.index)从标签中分离特征
把预测值分离出来
train_labels = train_dataset.pop("拍摄数量")
test_labels = test_dataset.pop("拍摄数量")数据规范化
使用不同的尺度和范围对特征归一化是好的实践。尽管模型可能 在没有特征归一化的情况下收敛,它会使得模型训练更加复杂,并会造成生成的模型依赖输入所使用的单位选择。
就是将数据统一差不多的大小
def norm(x):
return (x - train_stats['mean']) / train_stats['std']
normed_train_data = norm(train_dataset)
normed_test_data = norm(test_dataset)结果类似于
输入 :部门数 35 星期 3 日期 202
输出 :1.98 0.0 1.768
但是要注意 之后预测数据时 也要统一化
二.构建模型
构建
我们将会使用一个“顺序”模型,其中包含两个紧密相连的隐藏层,以及返回单个、连续值得输出层。
def build_model():
model = keras.Sequential([
layers.Dense(64, activation='relu', input_shape=[len(train_dataset.keys())]),
layers.Dense(64, activation='relu'),
layers.Dense(1)
])
optimizer = tf.keras.optimizers.RMSprop(0.001)
model.compile(loss='mse',
optimizer=optimizer,
metrics=['mae', 'mse'])
return model训练
# 通过为每个完成的时期打印一个点来显示训练进度
class PrintDot(keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs):
if epoch % 100 == 0: print('')
print('.', end='')
EPOCHS = 1000
history = model.fit(
normed_train_data, train_labels,
epochs=EPOCHS, validation_split = 0.2, verbose=0,
callbacks=[PrintDot()])预测值对比
最后进行预测值对比
error = test_predictions - test_labels
plt.hist(error, bins = 25)
plt.xlabel("Prediction Error [MPG]")
_ = plt.ylabel("Count")
第一篇完
tensorflow模型构建到此结束 想看详细教程 官网链接![]() https://www.tensorflow.org/tutorials/keras/regression
https://www.tensorflow.org/tutorials/keras/regression
后续写转tensorflow lite/部署方案、动态下发、端侧推断部分