大家好我是狗蛋,我们都知道,对于计算机来讲,所有东西都由一堆0和1组成。那么今天我们来了解计算机的0和1是怎么变成我们屏幕上看到的图片、视频和声音的?

其实这堆0和1和我们的语言是一个道理,比如说我们生活中的一个水果“苹果”,在中文用苹果表示,在英文中用apple表示,在日文里面是用アップル 表示的。

虽然表示方法不同,但苹果,apple アップル表示的都是一个意思,也就是说虽然语言不同表示一个东西的形式也不一样,但这些语言都有自己的规则。比如中文里面苹果就是苹果,英文里面苹果就是apple。那我们的计算机也一样,虽然在我们看来是一堆毫无规律组合起来的0和1。但他们也有相应的规则的。
这个规则对于计算机来说,就是编码表。这个编码表就像我们小时候的识字表一样,这个编码表包含了,我们看到的文字,标点符号等等。所对应的各种信息,比如说,计算机内部有“010010011”这样一串数字,那计算机就会在编码表里,找到这串数字的所对应的东西。然后在屏幕上把这个东西显示出来这样就有了我们看到的文字。
那我们看到的图片和视频又是怎么变成0和1呢?比如我们打开一张黑白图片,当我们吧一张图片发大之后,我们就会看到一个一个的小方块

这个小方块就是我们说的像素点,我们假设图片的每个像素点,只有一个二级制位,也就是说这个像素点用二进制来保存的话要么是0要么是1,也就是黑白图片。所以图片像素点的二级制越多,这个像素点可以表现的颜色就越丰富。比如一个像素点是两个二进制位的,那对于计算机来说,这个像素点要么是0要么是1,或者零一,再或者一零,4种情况。也就是说这个像素点可以显示四种颜色,那么我们一次类推,当一个像素点是8个二进制时,这个图片每个像素点,都有256个颜色可以显示,这就是图片在计算机内部的情况。
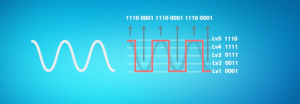
视频本质上就是一张一张连续播放的图片,所以视频和图片一个道理,那我们的声音是怎么变成0和1储存在计算机里面的呢?比如我用麦克风录了一段10秒的声音,声音的波形我们都知道,它是一个光滑的曲线,而我们的计算机需要尽可能的把这光滑的曲线再电脑上给模拟出来
所以第一步就是对这个曲线进行采样,比如计算机每秒,对这个声音采样一次采样完成之后,计算机就把这段10秒钟的声音在电脑上模拟出来了,但这个时候我们发现,模拟出来的声音的波形和原始声音的波形相差很大。

也就是说,电脑模拟的声音和原始声音有很大差别。那要怎样才能让模拟出来的声音曲线尽可能的像原始声音的曲线。这个时候,我们可以提高计算机的采样频率,从之前的一秒一次提高到一秒两次。总之就是采样的频率越高,那计算机模拟出来的曲线,就越接近于原始声音的曲线也就越能还原出原始的声音。

然后第二步,就是把刚才模拟出来的曲线进行量化,那量化是什么意思呢?就像我们考试成绩一样有51.60.70.71.99.100这些分数,但在公布成绩时,学校发现分数太多,一个个的公布成绩太麻烦。然后学校规定60分以下不合格,60-70为合格,71-100为优秀。把这些不同的分数分层3个不同的等级,之后学习公布成绩的时候说。我校本年度成绩不合格的人数5人,成绩合格人数100人,成绩优秀人数500人,这个就是我们说的量化。
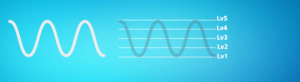
完成量化之后,就是最后一步进行编码我们假设量化等级一级等于0001,二级等于0011,然后依次类推,一次把这些等级记录成对应的0和1就可以了。到这里计算机就完成了把我们能听见的声音数字化的过程。